
If you look at the OpenRouter rankings right now, you’ll notice a massive trend. Chinese models (specifically the Qwen family) are dominating token consumption.
Scott Galloway posted a chart on LinkedIn about this. He called it “AI dumping from China” and warned of a market correction.
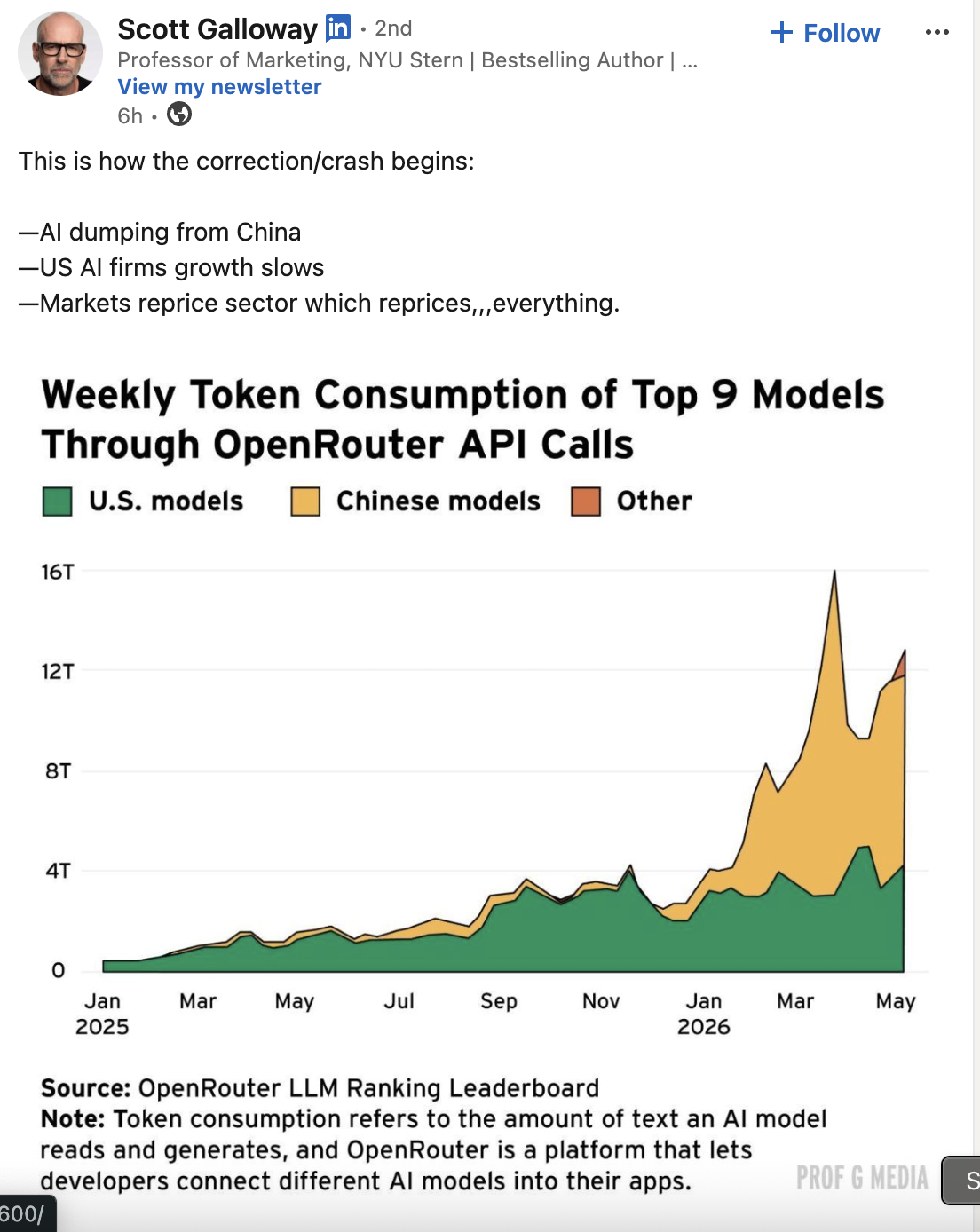
But Galloway’s narrative isn’t totally on the mark. This isn’t (just) a geopolitical trade war. I think the bigger factor is economics and developer ergonomics.
It’s the classic Cloud vs. On-Prem debate, reborn in the AI era.
The Cloud vs. On-Prem Corollary
For my passion project, BrandCast, I migrated from Gemini/Vertex to Qwen on OpenRouter.
The original architecture was built entirely on Google Cloud. We ran on GKE, MemoryStore, and Cloud SQL. It worked great.
But keeping a bare-minimum PoC environment idle cost ~$200 a month. A single research spike using Google’s Veo video generation cost $150.
For a bootstrapped startup, that’s real money. So I migrated to OpenRouter and fal.ai.
I did this to eliminate baseline idle costs and get a true pay-as-you-go setup.
I’m not the only one doing this. Increasingly, large organizations are running the exact same math.
We see this in the tooling. Open-source projects like LMSYS Org’s RouteLLM and the popular LiteLLM proxy exist specifically because companies want to optimize their token spend. They build routing gateways to triage queries. If a prompt is simple (like basic classification or formatting), the router sends it to a cheaper open model like Qwen or Llama. They only pay for expensive closed APIs when the task actually requires deep reasoning.
It’s not about self-funding. It’s about scale and cost control. It’s also a core part of what I call context-driven development. We’re moving from a world where we just buy a smart model to a world where we build a smart harness around a cheaper model.
The Operational Tax of “Cheap”
But moving to open models isn’t all puppies and rainbows.
With Gemini, the developer experience was seamless. The defaults were sane. The output was optimized. It just worked. And it was fast and (more importantly) consistent.
Qwen via OpenRouter introduced a massive amount of friction that I had to sort out.
We faced response latencies of 30 seconds. Reasoning models generated 1,800 thinking tokens just to output 40 tokens of text.
Sometimes, those thinking tokens bled directly into the output block.
We had to deal with inconsistent provider endpoints on OpenRouter. Some supported different context sizes. Others went down without warning.
We spent hours configuring cryptic, poorly-documented API parameters to prevent no-ops.
In short, we traded money for engineering sweat equity.
It’s the same decision developers have faced for decades: Cloud vs. On-Prem, or Managed vs. DIY.
You can pay a premium for a managed service that handles the complexity. Or you can save cash, roll your own system, and pay with your time.
Debunking the Quality Hype
So, is Gemini overpriced? No.
It’s the age-old technology choice. You plot how much time you want to invest and how much money you want to spend, plot it on a curve, and decide where you’re going to intersect.
The rise of Qwen on OpenRouter isn’t a backlash against the quality of US models. It’s a commentary on cost and developer ergonomics.
Developers are buying the cheapest raw commodity token available. They’re too expensive to do anything else at scale. Then, they’re engineering the quality they need around it.
If you have more capital than engineering hours, buy comfort. If you have more time than budget, get ready to sweat.